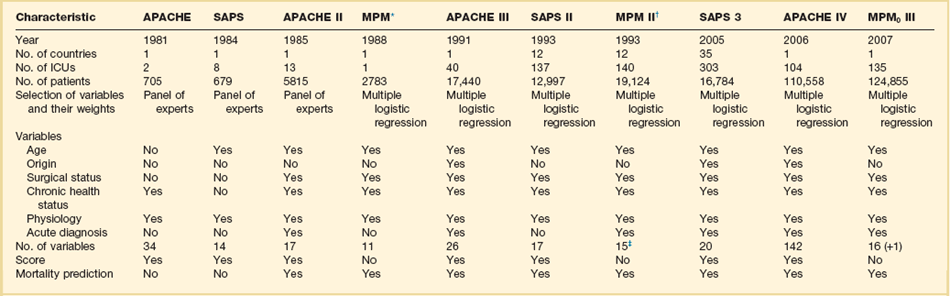
73 SEVERITY OF ILLNESS ASSESSMENT AND OUTCOME PREDICTION Selecting the Target Population Using a Severity of Illness Score Application of a Severity of Illness Score: Evaluation of Patients ORGAN DYSFUNCTION/FAILURE SCORING SYSTEMS Multiple Organ Dysfunction Score Sequential Organ Failure Assessment Score Logistic Organ Dysfunction System Score SCORING SYSTEMS FOR SPECIFIC CLINICAL CONDITIONS The goal of intensive care is to provide the highest quality of treatment in order to achieve the best outcomes for critically ill patients. Although intensive care medicine has developed rapidly over the years, there exists, still, little scientific evidence as to what treatments and practices are really effective in the real world. Moreover, intensive care now faces major economic challenges, which increase the need to provide evidence not only on the effectiveness but also on the efficiency of practices. Intensive care is, however, a complex process, which is carried out on very heterogeneous populations and is influenced by several variables, including cultural background and different structure and organization of the health care systems. It is, therefore, extremely difficult to reduce the quality of intensive care to something measurable, to quantify it and then to compare it among different institutions. Also, in recent years, patient safety as a necessary dimension in the evaluation of quality of the care provided has become mandatory, leading to major changes in the way benchmarking should be evaluated and reported.1 Although quality encompasses a variety of dimensions, the main interest to date is focused on effectiveness and efficiency: It is clear that other issues are less relevant if the care being provided is either ineffective or harmful. Therefore, the priority must be to evaluate effectiveness. The instruments available to measure effectiveness in intensive care derive from the science of outcome research. The starting point for this science was the high degree of variability in medical processes, which was found during the first part of the twentieth century, when epidemiologic research was developing. The variation in medical practices led to the search for the “optimal” therapy for each syndrome or disease through the repeated performance of randomized controlled trials (RCTs). However, the undertaking of RCTs in intensive care is fraught with ethical and other difficulties. For this reason, observational studies to evaluate the effects of intensive care treatment are still frequently employed and sometimes more informative than prior RCTs.2 Outcome research provides the methods necessary to compare different patients or groups of patients, especially different institutions. Risk adjustment (also called case-mix adjustment) is the method of choice to standardize the severity of illness of the individual or groups of patients. The purpose of risk adjustment is to take into account all of the characteristics of patients known to affect their outcome, in order to understand the differences due to the treatment received and the conditions (timing, setting, standardization) in which that treatment has been delivered. Conceptually, the quantification of individual patients should be made by the use of severity scores, and the evaluation of groups of patients is done by summing up the probabilities of death given by the model for each individual patient and its comparison with actual fatality. Scoring systems have been broadly used in medicine for several decades. In 1953 Virginia Apgar3 published a very simple scoring tool, the first general severity score designed to be applicable to a general population of newborn children. It was composed of five variables, easily evaluated at the patient’s bedside, that reflect cardiopulmonary and central nervous system function. Its simplicity and accuracy have never been improved on, and any child born in a hospital today receives an Apgar score at 1 and 5 minutes after birth. Nearly 50 years ago Dr. Apgar commented on the state of research in neonatal resuscitation: “Seldom have there been such imaginative ideas, such enthusiasms and dislikes, and such unscientific observations and study about one clinical picture.” She suggested that part of the solution to this problem would be a “simple, clear classification or grading of newborn infants which can be used as the basis for discussion and comparison of the results of obstetric practices, types of maternal pain relief and the effects of resuscitation.” Thirty years later, physicians working in ICUs found themselves using the same tools and applying them in the same way. Efforts to improve risk assessment during the 1960s and 1970s were directed at improving our ability to quickly select those patients most likely to benefit from promising new treatments. For example, Child and Turcotte4 created a score to measure the severity of liver disease and estimate mortality risk for patients undergoing shunting. In 1967, Kilipp and Kimball classified the severity of acute myocardial infarction by the presence and severity of signs of congestive heart failure.5 In 1974 Teasdale and Jennett introduced the Glasgow Coma Scale (GCS) for reproducibly evaluating the severity of coma.6 The usefulness of the GCS score has been confirmed by the consistent relationship between poor outcome and a reduced score among patients with a variety of diseases. The GCS score is reliable and easy to perform, but problems with the timing of evaluation, the use of sedation, inter- and intraobserver variability, and its use in prognostication have caused strong controversies.7 Nevertheless, the GCS remains the most widely used neurologic measure for risk assessment. The 1980s brought an explosive increase in the use of new technology and therapies in critical care. The rapidity of change and the large and growing investment in these high-cost services prompted demands for better evidence for the indications and benefit of critical care. For this reason several researchers developed systems to evaluate and compare the severity of illness and outcome of critically ill patients. The first of these systems was the Acute Physiology And Chronic Health Evaluation (APACHE) system, published by Knaus and associates in 1981,8 followed soon after by Le Gall and colleagues with the Simplified Acute Physiology Score (SAPS).9 The APACHE system was latter updated to APACHE II,10 and a new system, the Mortality Probability Model (MPM), joined the group.11 By the beginning of the 1990s different systems were available to describe and classify ICU populations, to compare severity of illness, and to predict mortality risk in their patients. These systems performed well, but there were concerns about errors in prediction caused by differences in patient selection and lead-time bias. There were also concerns about the size and representativeness of the databases used to develop the three systems and about poor calibration within patient subgroups and across geographic locations. These concerns, in part, led to the development of their subsequent versions such as APACHE III,12 the SAPS II,13 and the MPM II,14 all published between 1991 and 1993. During the mid-1990s, the need to quantify not only mortality but also morbidity risks in specific groups of patients became evident and led to the development of the so-called organ dysfunction scores, such as the Multiple Organ Dysfunction Score (MODS),15 the Logistic Organ Dysfunction System (LODS) score,16 and the Sequential Organ Failure Assessment (SOFA) score.17 • Severity scores are instruments that aim at stratifying patients based on their severity, assigning to each patient an increasing score as the severity of the illness increases. • Outcome prediction models, apart from their ability to stratify patients according to their severity, aim at predicting a certain outcome (usually the vital status at hospital discharge) based on a given set of prognostic variables and a certain modeling equation. The development of this kind of system, applicable to heterogeneous groups of critically ill patients, started in the 1980s (Table 73.1). The first general severity of illness score applicable to most critically ill patients was the APACHE score.8 Developed in the George Washington University Medical Center in 1981 by William Knaus and coworkers, the APACHE system was created to evaluate, in an accurate and reproducible form, the severity of disease in this population.18–20 Two years later, Jean-Roger Le Gall and coworkers published a simplified version of this model, the SAPS.21 This model soon became very popular in Europe, especially in France. Another simplification of the original APACHE system, the APACHE II, was published in 1985 by the same authors of the original model.10 This system introduced the prediction of mortality risk, providing a major reason for ICU admission from a list comprising 50 operative and nonoperative diagnoses. The MPM,22 developed by Stanley Lemeshow, provided additional contributions for the prediction of prognosis, using logistic regression techniques. Further developments in this field include the third version of the APACHE system (APACHE III)12 and the second versions of the SAPS (SAPS II)13 and MPM (MPM II).14 All of them use multiple logistic regression to select and weight the variables and are able to compute the probability of hospital mortality risk for groups of critically ill patients. It has been demonstrated that they perform better than their old counterparts,23,24 and they represented the state of the art in this field by the end of the last century. Table 73.1 General Severity Scores and Outcome Prediction Models *These models are based on previous versions, developed by the same investigators (Lemeshow et al11,181; see online list of references for this chapter). †The numbers presented are those for the admission component of the model (MPM II0). MPM II24 was developed using data for 15,925 patients from the same ICUs. Since the early 1990s, owing to the progressive lack of calibration of these models, the performance of these instruments began to slowly deteriorate with the passage of time. Differences in the baseline characteristics of the admitted patients, in the circumstances of the ICU admission, and in the availability of general and specific therapeutic measures introduced an increasing gap between actual mortality rate and predicted mortality risk.25 Overall, in the last years of the century, there was an increase in the mean age of the admitted patients, a larger number of chronically sick patients and immunosuppressed patients, and an increase in the number of ICU admissions due to sepsis.26,27 Although most of the models kept an acceptable discrimination, their calibration (or prognostic accuracy) deteriorated to such a point that major changes were needed. An inappropriate use of these instruments outside their sampling space was responsible also for some misapplication of the instruments, especially for risk adjustment in clinical trials.28–30 In the early 2000s, several attempts were made to improve the old models. However, a new generation of general outcome prediction models was built that included models such as the MPM III developed in the IMPACT database in the United States,31 new models based on computerized analysis by hierarchical regression developed by some of the authors of the APACHE systems,32 the APACHE IV,33 and the SAPS 3 admission model, developed by hierarchical regression in a worldwide database.34,35 Models based on other statistical techniques such as artificial neural networks and genetic algorithms have been proposed but, besides academic use, they never became used widely.36,37 These approaches have been revised more than once,38 and will be summarized later. All the existing general outcome prediction models used logistic regression equations to estimate the probabilities of a given outcome in a patient with a certain set of predictive variables. Consequently, the first approach to improve the calibration of a model when the original model is not able to adequately describe the population is to customize the model.39 Several methods and suggestions have been proposed for this exercise,40 based usually on one of two strategies: • First-level customization, or the customization of the logit, developing a new equation relaying the score to the probability, such as one proposed by Le Gall or Apolone.41,42 • Second-level customization, or the customization of the coefficients of the variables in the model as described for the MPM II0 model,39 which can be made either by keeping unchanged the relative weight of the variables in the model or eventually by changing also these weights (this latter technique involves the limit of second-level customization: from this point forward, so the researcher is developing a new model and not customizing an existing one). Usually the researcher customizing an existing model assumes that the relative weight of the variables in the model is constant. Both of these methods have been used in the past with a partial success in increasing the prognostic ability of the models.39,43 However, both fail when the problem of the score is on discrimination or in its poor performance in subgroups of patients (poor uniformity of fit).44 This fact can be justified by the lack of additional variables, more predictive in this specific context. The addition of new variables to an existing model has been done before45,46 and can be an appropriate approach in some cases. It can lead to very complex models, needs the collection of special data, and is also more expensive and time-consuming. The best tradeoff between the burden of data collection and accuracy should be tailored case by case. It should be noted that the aim of first-level customization, which is nothing more than a mathematical translation of the original logit in order to get a different probability of mortality risk, is to improve the calibration of a model and not to improve discrimination. It should therefore not be considered when the improvement of this parameter is considered important. A third level of customization can be imagined, through the introduction in the model of new prognostic variables and the recomputation of the weights and coefficients for all variables, but—as mentioned before—this technique crosses the borders of customizing a model versus building a new predictive model. In past years, all these approaches have been tried.47–49 Three general outcome prediction models have been developed and finally published: the SAPS 3 admission model in 2005, the APACHE IV in 2006, and the MPM III in 2007.50 Developed by Rui Moreno, Philipp Metnitz, Eduardo Almeida, and Jean-Roger Le Gall on behalf of the SAPS 3 Outcomes Research Group, the SAPS 3 model was published in 2005.34,35 The study used a total of 19,577 patients consecutively admitted to 307 ICUs all over the world from 14 October to 15 December 2002. This high-quality multinational database was built to reflect the heterogeneity of current ICU case mix and typology all over the world, trying not to focus only on Western Europe and the United States. Consequently, the SAPS 3 database better reflects important differences in patients’ and health care systems’ baseline characteristics that are known to affect outcome. These include, for example, different genetic makeups, different styles of living, and a heterogeneous distribution of major diseases within different regions, as well as issues such as access to the health care system in general and to intensive care in particular, or differences in availability and use of major diagnostic and therapeutic measures within the ICUs. Although the integration of ICUs outside Europe and the United States surely increased its representativeness, it must be acknowledged that the extent to which the SAPS 3 database reflects case mix on ICUs worldwide cannot be determined yet. Based on data collected at ICU admission (±1 hour), the authors developed regression coefficients by using multilevel logistic regression to estimate the probability of hospital death. The final model, which comprises 20 variables, exhibited good discrimination without major differences across patient typologies; calibration was also satisfactory. Customized equations for major areas of the world were computed and demonstrate a good overall goodness of fit. It is interesting that the determinant of hospital mortality probability changed remarkably from the early 1990s,12 with chronic health status and circumstances of ICU admission now being responsible for almost three fourths of the prognostic power of the model. To allow all interested parties to see the calculation of SAPS 3, completely free of charge, extensive electronic supplementary material (http://dx.doi.org/10.1007/s00134-005-2762-6 and http://dx.doi.org/10.1007/s00134-005-2763-5, both accessed 30/06/2013) was published together with the study reports, including the complete and detailed description of all variables as well as additional information about SAPS 3 performance. Moreover, the SORG provides at the project website (www.saps3.org) several additional resources: First, a Microsoft Excel sheet is available and can be used to calculate a SAPS 3 “on the fly.” Second, a small Microsoft Access database allows for the calculation, storage, and export of SAPS 3 data elements. However, as all outcome prediction models, SAPS 3 is slowly losing calibration, as recently demonstrated by several groups.51–55 It seems to keep a good level of reliability and discrimination, but a recalibration process, which can be relatively easy to perform, must be done in the following years. In early 2006, Jack E. Zimmerman, one of the original authors of the original APACHE models, published in collaboration with colleagues from Cerner Corporation (Vienna, VA) the APACHE IV model.33 The study was based on a database of 110,558 consecutive admissions during 2002 and 2003 to 104 ICUs in 45 U.S. hospitals participating in the APACHE III database. The APACHE IV model uses the worst values during the first 24 hours in the ICU and a multivariate logistic regression procedure to estimate the probability of hospital death. Predictor variables were similar to those in APACHE III, but new variables were added and different statistical modeling has been used. The accuracy of APACHE IV predictions was analyzed in the overall database and in major patient subgroups. APACHE IV had good discrimination and calibration. For 90% of 116 ICU admission diagnoses, the ratio of observed to predicted mortality was not significantly different from 1.0. Predictions were compared with the APACHE III versions developed 7 and 14 years previously: there was little change in discrimination, but aggregate mortality risk was systematically overestimated as model age increased. When examined across disease, predictive accuracy was maintained for some diagnoses but for others seemed to reflect changes in practice or therapy. A predictive model for risk-adjusted ICU length of stay was also published by the same group.56 More information about the model and the possibility to compute the probability of death for individual patients is available at the website of Cerner Corporation (www.criticaloutcomes.cerner.com). The MPM0 III was published by Tom Higgins and associates in 2007.50 It was developed using data from ICUs in the United States participating in the project IMPACT but there is almost no published data to evaluate its behavior outside the development cohort. As for the previous MPM models, the MPM0 III does not allow the computation of a score but estimates directly the probability of death in the hospital. Fatality meets all the preceding criteria; however, there are confounding factors to be considered when using death as an outcome. The location of the patient at the time of death can considerably reduce hospital mortality rates. For example, in a study of 116,340 ICU patients, a significant decline in the ratio of observed and predicted death was attributed to a decrease in hospital mortality rate as a result of earlier discharge of patients with a high severity of illness to skilled nursing facilities.57 In the APACHE III study, a significant regional difference in mortality rate was entirely secondary to variations in hospital length of stay.58 Improvements in therapy, such as the use of thrombolysis in myocardial infarction or steroids in Pneumocystis pneumonia and the acquired immunodeficiency syndrome59 can dramatically reduce hospital mortality rate. Increases in the use of advance directives, do-not-resuscitate orders, and limitation or withdrawal of therapy all increase hospital mortality rates. Variations in any of the previous factors will lead to differences between observed and predicted deaths that have little to do with case mix or effectiveness of therapy. Predictive instruments directed at long-term mortality predictions provide accurate prognostic estimates within the first month of hospital discharge, but their accuracy falls off considerably thereafter, because other factors, such as HIV infection or malignancy, dominate the long-term survival pattern.45 Owing to these caveats, fatality is the most useful outcome for designing general severity of illness scores and predictive instruments. • Morbidity and complication rates • Duration of mechanical ventilation, use of pulmonary artery catheters • Quality of life after ICU/hospital discharge All current outcome prediction models aim at predicting vital status at hospital discharge. It is thus incorrect to use them to predict other outcomes, such as the vital status at ICU discharge. This approach will result in a gross underestimation of mortality rates.60 The next step in the development of a general outcome prediction model is the evaluation, selection, and registration of the predictive variables. At this stage major attention should be given to the variable definitions as well as to the time frames for data collection.61–63 Very frequently models have been applied incorrectly, the most common errors being related to the following: • The definitions of the variables • The time frames for the evaluation and registration of the data • The frequency of measurement and registration of the variables • The applied exclusion criteria It should be noted that all existing models have been calibrated for nonautomated (i.e., manual) data collection. The use of electronic patient data management systems (with high sampling rates) has been demonstrated to have a significant impact on the results:64,65 the higher the sampling rate, the more outliers will be found and thus scores will be higher. The evaluation of intra- and interobserver reliability should always be described and reported, together with the frequency of missing values. • Readily available and clinically relevant • Plausible relationship to outcome and easily defined and measured • Independent of treatment processes Initial selection of variables can be either deductive (subjective), using terms that are known or suspected to influence outcome, or inductive (objective) using any deviation from homeostasis or normal health status. The deductive approach employs a group of experts, who supply a consensus regarding the measurements and events most strongly associated with the outcome. This approach is faster and requires less computational work; APACHE I and SAPS I both started this way. A purely inductive strategy, used by MPM, begins with the database, and tests candidate variables with a plausible relationship to outcome. In the SAPS 3 model several complementary methods have been used, such as logistic regression on mutually exclusive categories built using smoothed curves based on LOWESS (locally weighted scatterplot smoothing),66 and multiple additive regression trees (MART).67 • Chronic disease status or comorbid conditions • Circumstances of ICU admission • Reasons for ICU admission and admitting diagnoses • Cardiopulmonary resuscitation (CPR), mechanical ventilation prior to ICU admission • Location and length of stay before admission The accuracy of any scoring system depends on the quality of the database from which it was developed. Even with well-defined variables, significant interobserver variability is reported.68,69 In calculating the scores, several practical issues should be discussed.70,71 First, exactly which value for any parameter should be considered? It is true that for many of the more simple variables, several measurements will be taken during any 24-hour period. Should the lowest, highest, or an average be taken as the representative value of that day? There is a general consensus that, for the purposes of the score, the worst value in any 24-hour period should be considered. Second, what about missing values? Should the last known value repeatedly be considered as representative until a new value is obtained, or should the mean value between two successive values be taken? Both options make assumptions that may influence the reliability of the score. The first option assumes that we have no knowledge of the evolution of values with time and the second assumes that changes are usually fairly predictable and regular. However, we prefer this second option because values may be missing for several days and repeating the last known value may involve considerable errors in calculation. In addition, changes in most of the variables measured (platelet count, bilirubin, urea) are, in fact, usually fairly regular, moving up or down in a systematic manner.
Severity of Illness Scoring Systems
Historical Perspective
Severity of Illness Assessment and Outcome Prediction
Recalibrating and Expanding Existing Models
Building New Models
The SAPS 3 Admission Model
The APACHE IV Model
The MPM0 III Model
Developing Predictive Models
Outcome Selection
Data Collection
Selection of Variables
Validation of the Model
Related posts:
 Cardiac Arrest and Cardiopulmonary Resuscitation
Cardiac Arrest and Cardiopulmonary Resuscitation
 Use of Sedatives, Analgesics, and Neuromuscular Blockers
Use of Sedatives, Analgesics, and Neuromuscular Blockers
 Traumatic Shock and Tissue Hypoperfusion: Nonsurgical Management
Traumatic Shock and Tissue Hypoperfusion: Nonsurgical Management
 Intensive Care of the Cancer Patient
Intensive Care of the Cancer Patient
 Pneumonia: Considerations for the Critically Ill Patient
Pneumonia: Considerations for the Critically Ill Patient
 Ethical Considerations in Managing Critically Ill Patients
Ethical Considerations in Managing Critically Ill Patients

Full access? Get Clinical Tree


Severity of Illness Scoring Systems
