Chapter 3 Severity of illness and likely outcome from critical illness
At present scoring systems are not sufficiently accurate to make outcome predictions for individual patients.
Perhaps the earliest reference to grading illness was in an Egyptian papyrus which classified head injury by severity.1 More recently it has been the constellation of physiological disturbances for specific conditions which popularised an approach which linked physiological disturbance to outcome in the critically ill. Examples include the Ranson score for acute pancreatitis,2 the Pugh modification of Child–Turcotte classification for patients undergoing portosystemic shunt surgery and now widely used for classification of end-stage liver disease,3 Parsonnet scores for cardiac surgery4 and the Glasgow Coma Score (GCS) for acute head injury.5 The earliest attempts to quantify severity of illness in a general critically ill population was by Cullen et al.6 who devised a therapeutic intervention score as a surrogate for illness. This was followed in 1981 with the introduction of the Acute Physiology, Age and Chronic Health Evaluation (APACHE) scoring system by Knaus et al.7 Since then numerous scoring systems have been designed and tested in populations across the world.
The potential advantages of quantifying critical illness include:
The least controversial use for scoring systems has been as a method for comparing patient groups in clinical trials. While this seems to have been widely accepted by the critical care community, there has been less enthusiasm to accept the same systems as comparators for between-unit and even between-country performances, unless of course your performance is good. Most clinicians agree that scoring systems have limited value for individual patient decision pathways, although recently an APACHE II score above 25 under appropriate circumstances has been included in the guidelines for the administration of recombinant human activated protein C for severe sepsis and septic shock. Much of the sceptical views among clinicians are based on studies which show poor prognostic performance from many of the models proposed.8–14 The fundamental problem for these scores and prognostic models is poor calibration for the cohort of patients studied, often in countries with different health service infrastructures, to where the models were first developed. Other calibration issues arise either because there is poor adherence to the rules for scoring methodology by users, or patient outcomes improve following introduction of new techniques and treatments or models failed to include important prognostic variables. For example it has become clearer that prognosis is as much affected by local organisation, patient pathways, location prior to admission and preadmission state as it is by acute physiological disturbances.15,16
Score systems would be better calibrated if developed from a narrow number of countries with similar health services. However this limits their international usefulness for clinical studies. The latter can be improved by score systems developed from a wider international cohort; however when used for an individual country it can be expected to calibrate poorly. Simplified Acute Physiology Score 3 (SAPS 3: developed across the globe) has provided customisation formulae so that the risk-adjusted expected mortality can be related to the geographical location of the unit.16
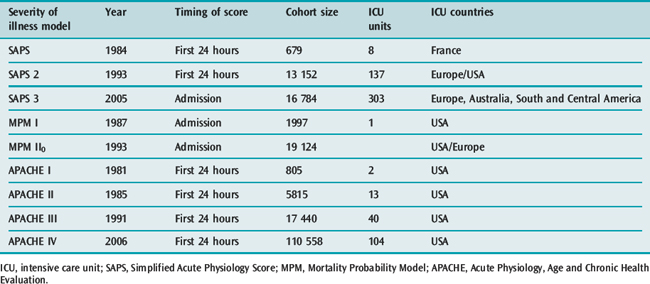
Inevitably, as advances occur, risk-adjusted mortality predictions become outdated with some old models overestimating expected mortality14,17 and others underestimating observed mortality.18 The designers of the scoring systems have recognised the changing baselines and review the models every few years, Table 3.1 outlines some characteristics of the upgraded systems.
Table 3.1 Revision dates for the most common internationally recognized risk adjusted models for mortality prediction
PHYSIOLOGICAL DISTURBANCE
PRIMARY PATHOLOGICAL PROCESS
The primary pathology leading to intensive care admission has a significant influence on prognosis. Therefore, for a given degree of acute physiological disturbance, the most serious primary pathologies or underlying conditions are likely to have the worst predicted outcomes. For example, similar degrees of respiratory decompensation in an asthmatic and a patient with haematological malignancy are likely to lead to different outcomes. Furthermore the potential reversibility of a primary pathological process, whether spontaneous or through specific treatment, also greatly influences outcome, e.g. patients with diabetic ketoacidosis can be extremely unwell but insulin and volume therapy can rapidly reverse the physiological disturbance.
PHYSIOLOGICAL RESERVE, AGE AND COMORBIDITY
UNIT ORGANISATION AND PROCESSES
Soon after the introduction of APACHE II it was recognised that units with effective teams, nursing and medical leadership, good communications and run by dedicated intensive care specialists potentially had better outcomes than those without such characteristics.19–21
RISK-ADJUSTED EXPECTED OUTCOME AND ITS MEASUREMENT
Physiological disturbance, physiological reserve, pathological process and mode of presentation can be related to expected outcome by statistical methods. Common outcome measures for clinical trials are ICU mortality, or mortality at 28 days; however most models used for risk-adjusted mortality prediction are based on hospital mortality. Patient morbidity might also be considered nearly as important an endpoint as mortality, since many patients survive with serious functional impairment.22,23 For socioeconomic reasons there would be a strong argument to consider 1-year survival and time to return to normal function or work as endpoints.24,25 These latter measures however have been more closely related to chronic health status.
Hospital mortality is the most common outcome measure because it is frequent enough to act as a discriminator and is easy to define and document.
PRINCIPLES OF SCORING SYSTEM DESIGN
CHOICE OF INDEPENDENT PHYSIOLOGICAL VARIABLES AND THEIR TIMING
The designers of the original APACHE and SAPS systems chose variables which they felt would represent measures of acute illness. The chosen variables were based on expert opinion weighted equally on an arbitrary increasing linear scale, with the highest value given to the worst physiological value deviating from normal.26,27 Premorbid conditions, age, emergency status and diagnostic details were also included in these early models and from these parameters a score and risk of hospital death probability could be calculated. Later upgrades to these systems, SAPS 2, APACHE III and the MPM,28 used logistic regression analysis to determine the variables which should be included to explain the observed hospital mortality. Variables were no longer given equal importance but different weightings and a logistic regression equation were used to calculate a probability of hospital death. The more recent upgrades, APACHE IV and SAPS 3, have continued to use logistic regression techniques to identify variables that have an impact on hospital outcome.
The extent of physiological disturbance changes during critical illness. Scoring systems therefore needed to predetermine when the disturbance best reflected the severity of illness which additionally facilitated discrimination between likely survivors and non-survivors. Most systems are based on the worst physiological derangement for each parameter within the first 24 hours of ICU admission. However some systems, such as MPM II0, are based on values obtained 1 hour either side of admission; this is designed to avoid the bias that treatment might introduce on acute physiology values.29
DEVELOPING A SCORING METHODOLOGY AND ITS VALIDATION
All the scoring systems have been based on a large database of critically ill patients, usually derived from at least one country and from several ICUs (Table 3.2). Typically, in the more recent upgrades of the common scoring systems, part of the database is used to develop a logistic regression equation with a dichotomous outcome – survival or death, while the rest of the database is used to test out the performance of the derived equation. The equation includes those variables which are statistically related to outcome. Each of these variables is given a weight within the equation. The regression equation can be tested, either against patients in the developmental dataset using special statistical techniques such as ‘jack-knifing’ and ‘boot-strapping’ or against a new set of patients – the validation dataset – who were in the original database but not in the developmental dataset. The aim of validation is to demonstrate that the derived model from the database can be used not only to measure severity of illness but also to provide hospital outcome predictions.
Table 3.2 Ability of scores to discriminate correctly between survivors and non-survivors when tested on similar casemixes. A value of 1 represents perfect prediction
| Score | Area under ROC curve |
|---|---|
| APACHE II | 0.85 |
| APACHE III | 0.90 |
| SAPS 2 | 0.86 |
| MPM II0 | 0.82 |
| MPM II24 | 0.84 |
| SAPS 3 | 0.84 |
| APACHE IV | 0.88 |
ROC, receiver operating characteristic; APACHE, Acute Physiology, Age and Chronic Health Evaluation; SAPS, Simplified Acute Physiology Score; MPM, Mortality Probability Model.
In a perfect model the aim would be that:
DISCRIMINATION
The discriminating power of a model can be determined by defining a series of threshold probabilities of death such as 50, 70, 80% above which a patient is expected to die if their calculated risk of death exceeds these threshold values and then comparing the expected number of deaths with what was observed in those patients at the various probability cut-off points. For example, the APACHE II system revealed a misclassification rate (patients predicted to die who survived and those predicted to survive who died) of 14.4, 15.2, 16.7 and 18.5% at 50, 70, 80 and 90% cut off points above which all patients with such predicted risks were expected to die. These figures indicate that the model predicted survivors and non-survivors best i.e., discriminated likely survivors from non-survivors when it was assumed that any patient with a risk of death greater than 50% would be a non-survivor.
A conventional approach to displaying discriminating ability is to plot sensitivity, true positive predictions on the y-axis against false-positive predictions (1 – specificity) on the x-axis for several predicted mortality cut-off points, and producing a receiver operator characteristic curve (ROC) (Figure 3.1).
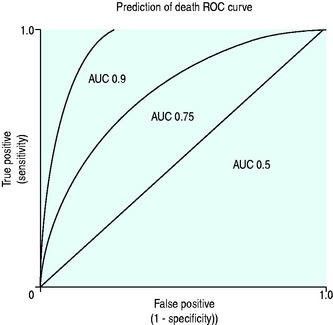
The ROC area under the curve (AUC) summarises the paired true-positive and false-positive rates at different cut-off points (Figure 3.1) and provides a curve which defines the overall discriminating ability of the model. A perfect model would show no false positives and would therefore follow the y-axis and has an area of 1, a model which is non-discriminating would have an AUC 0.5, whereas models which are considered good would have AUC greater than 0.8. The AUC can therefore be used for comparing discriminating ability of severity of illness predictor models.
CALIBRATION
A model with good calibration is one that for a given cohort predicts a similar percentage mortality as that observed. (Hosmer–Lemeshow goodness-of-fit C statistic compares the model with the patient group.)30
Observations with many models have revealed that, unless the casemix of the test patients is similar to that used to develop the model, the models may underperform due to poor calibration. This is particularly true when the testing is done for patients in different countries.12,16,31,32







